문자열을 보다 효율적으로 탐색할 수 있도록 저장하는 자료구조인 트라이(Trie)에 대해 알아본다.
1. 개요
데이터의 빠른 탐색을 위한 자료구조라고 하면 보통 이진탐색트리나 B트리, 해시테이블 등을 떠올릴 것이다. 이러한 자료구조들의 삽입/탐색 연산은 데이터의 갯수(N)에 영향을 받는다. 이번에 알아볼 트라이(Trie)는 문자열을 저장하고 효율적으로 탐색하기 위한 자료구조로, 특이하게도 데이터의 갯수가 아닌 삽입하거나 탐색할 데이터(문자열)의 크기에 영향을 받는다.
2. 삽입 연산
예시로 트라이에 'hello' 라는 데이터를 삽입해보자.

먼저 루트노드의 자식노드중 키 값이 'h' 인 노드를 찾는다 현재 트라이는 비어있기 때문에 루트노드의 자식 중에는 'h'를 키값으로 가진 노드는 존재하지 않는다. 그러면 'h'를 키 값으로 하는 노드를 생성하여 루트노드의 자식노드로 집어넣는다.

이제 새로 집어넣은 'h'를 키 값으로 하는 노드로 위치를 옮겨, 그 노드의 자식노드중 다음 문자인 'e'를 키값으로 하는 노드를 찾는다. 이번에도 'h' 노드의 자식노드는 비어있기 때문에 노드를 새로 만들어서 추가한다. 이것을 다섯글자 모두 삽입할 때 까지 반복한다.

이것으로 'hello' 의 삽입이 완료되었다. 다음은 트라이에 'head' 를 집어넣어보자. 루트노드에서 시작하여 글자를 하나하나 비교해나간다. 이번에는 첫 글자 h가 루트노드의 자식노드에 존재한다. 해당노드로 위치를 옮긴다.

다음은 'e'를 찾는다. 이번에도 'h' 노드의 자식노드에 'e'가 존재한다. 또다시 위치를 옮긴다.
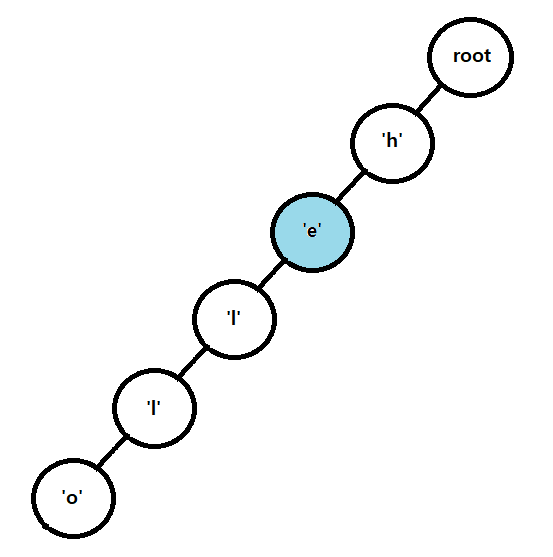
이번에는 'e' 노드의 자식노드에 'a' 가 존재하지 않는다. 'a' 노드를 생성하여 자식노드에 삽입하고 삽입한 노드로 위치를 이동한다.
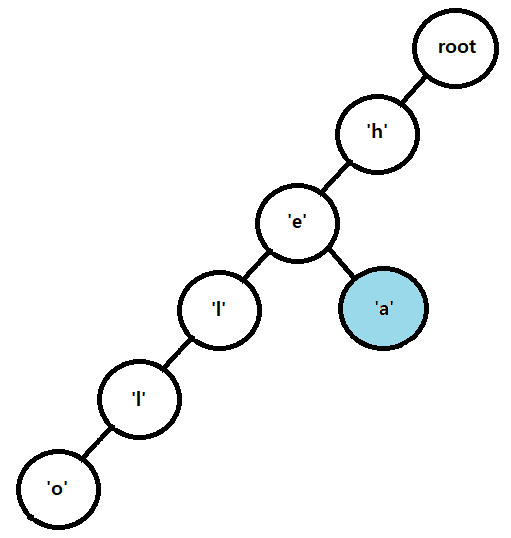
마지막으로 'd'가 'a' 노드의 자식노드에 존재하지 않기 때문에 노드를 생성하여 집어넣어준다.

이것으로 'head'의 삽입이 완료되었다.
그림으로만 살펴봐도 알겠지만 삽입과정이 굉장히 단순하다. 루트노드에서 시작하여 자식노드에서 데이터를 이루는 요소를 순차적으로 탐색해나가다가 존재하지 않는다면 생성하여 삽입해주는 방식이다. 물론 삽입 연산의 시간복잡도는 길이 L 인 문자열에 대해 O(L) 이다.
3. 탐색
탐색 알고리즘도 삽입과 거의 동일한 방식으로 이뤄진다. 다만 삽입 연산에서는 자식노드에 원하는 문자를 키 값으로 가진 노드가 없다면 만들어서 삽입하였지만 탐색의 경우 탐색에 실패했다는 결과가 바로 반환된다.

삽입 연산에서와 달리 일부 노드에 *표시가 있는 것을 확인할 수 있다. 이는 한 데이터의 끝을 표현한다. 데이터를 삽입할 때, 마지막 요소를 삽입할 경우 이 노드에서 끝나는 데이터가 존재함을 표시해주는 것으로 삽입하지 않은 데이터를 존재하는 것으로 오인할 위험을 미연에 방지하는 것이다. 예를들어 위 트라이에서 'hell'을 탐색해보자.

이와 같이 'h', 'e', 'l', 'l' 네 글자 모두 탐색에 성공하였다. 하지만 'hell' 이라는 문자열은 삽입된 적이 없으며 단지 'hello'가 삽입되었기 때문에 탐색이 가능했을 뿐이다. 만약 데이터의 끝을 표시하지 않았다면 이 상황에 hell이 정말 들어있는 것인지 아닌지 구분할 방법이 없지만 *로 데이터의 마지막 노드에는 표시를 해두었기 때문에 'hell'이라는 문자열이 존재하지 않는다는 사실을 알 수 있다.
4. 구현
Python으로 트라이를 간단하게 구현한 코드는 다음과 같다.
# 트라이의 노드 클래스
# data(키 값), child(자식노드 목록), finished(데이터의 마지막 노드인지 여부)의 세 필드값을 가진다.
class Node:
def __init__(self, data=None, finished=False):
self.data = data
self.finished = finished
self.child = {}
# 트라이 클래스
class Trie:
# 생성시 빈 노드를 생성하여 루트노드로 설정
def __init__(self):
self.root = Node()
# 삽입 메소드
def add(self, e):
# 루트 노드에서 탐색 시작
cur = self.root
# 데이터의 각 요소를 키 값으로 하는 노드를 타고내려간다.
for i in e:
# 현재 노드의 자식노드 중에
# 다음 요소를 키 값으로 하는 노드가 존재하지 않는다면 노드를 생성
# 현재 노드의 자식노드 리스트에 삽입한다.
if i not in cur.child:
cur.child[i] = Node(i)
cur = cur.child[i]
# 현재 노드가 데이터의 마지막 요소를 키값으로 하는 노드임을 표시
cur.finished = True
# 탐색 메소드
def search(self, key):
# 루트 노드에서 탐색 시작
cur = self.root
# 데이터의 각 요소를 키 값으로 하는 노드를 타고내려간다.
for c in key:
# 현재 노드의 자식노드 중에
# 다음 요소를 키 값으로 하는 노드가 존재하지 않는다면 노드를 생성
# 찾으려는 데이터가 존재하지 않음을 결과로 반환한다.
if c in cur.child:
cur = cur.child[c]
else:
return None
# 탐색이 종료됐을 때, 마지막 노드가 데이터의 마지막 요소를 키 값으로 하는 노드로
# 표시되어있다면 탐색 성공. 그렇지 않다면 데이터가 존재하지 않음을 결과로 반환한다.
return cur.data if cur.finished else None
'코딩테스트 > 알고리즘' 카테고리의 다른 글
| #33 누적 합(Prefix Sum) - 1차원 (0) | 2021.09.11 |
|---|---|
| #32 문자열 탐색 - 트라이(Trie) 2 (0) | 2021.09.09 |
| #31 문자열 탐색 - KMP 알고리즘(2) (0) | 2021.09.07 |
| #30 문자열 탐색 - KMP 알고리즘(1) (0) | 2021.09.06 |
| #29 동적 계획법 4 - 경우의 수 (0) | 2021.09.04 |