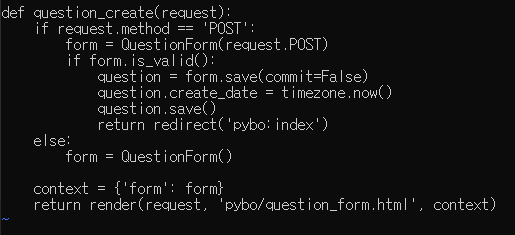
큐는 대기열이라는 이름 그대로 먼저 들어온 데이터가 먼저 추출되는 선입선출(FIFO)의 선형 자료구조이다.
스택이 top 에서만 삽입/삭제가 이루어졌던 것에 비해 큐의 경우 삭제만 이루어지는 front 와 삽입만 이루어지는
rear 로 이루어진다. 주요 연산은 다음과 같다.
데이터 삽입
enqueue(e) : 데이터 e를 큐의 맨 뒤인 rear 에 삽입한다.
데이터 삭제
dequeue() : 큐의 맨 앞인 front 의 데이터를 제거하고 제거된 데이터를 반환한다.
2. 큐의 활용
그래프의 너비 우선 탐색에 활용된다.
OS의 스케줄링에서 프로세스들의 요청을 저장하거나 인터넷/전화 회선상에서 고객의 요청을 저장하는 등 요청이 쌓이는 속도가 처리속도보다 빠른 경우라면 거의 대부분 유용하게 사용된다.
3. 파생 자료구조
데크(Dequeue)
일반적인 큐와 달리 front 와 rear 양쪽에서 삽입/삭제가 모두 가능한 자료구조
스택과 큐의 기능을 합쳐놓은 듯한 자료구조이다.
우선순위 큐
들어간 순서가 나오는 순서가 되는 일반적인 큐와 달리 나중에 들어갔어도 지정된 우선순위가 보다 높은 데이터가 먼저 추출되는 큐
배열이나 리스트로 구현할 경우 우선순위에 맞는 위치에 삽입하기 위해 O(N)의 시간복잡도를 보이기 때문에 O(logN)의 시간복잡도로 삽입 가능하며 항상 최솟값 혹은 최댓값이 먼저 추출되도록 할 수 있는 heap 을 사용하여 구현된다. 이에 대해서는 heap 을 설명할 때 자세히 다루기로 한다.
원형 큐
큐의 front 와 rear가 맞닿아있는 형태의 큐
원형 연결 리스트와 거의 동일하며 실제로 원형 연결 리스트를 그대로 원형 큐처럼 사용할 수 있다.
Datas:
head : 첫 노드를 가리키는 포인터
tail : 마지막 노드를 가리키는 포인터
it : 이터레이션을 위한 포인터
size : 리스트의 크기 = 리스트에 들어있는 노드의 갯수
Operations:
insert(e, i) : 데이터 e를 리스트의 i번째 위치에 삽입. i == -1이라면 마지막에 삽입
delete_at(i) : i 번째 데이터를 삭제하고 삭제한 데이터를 반환
delete(e) : 데이터 e를 찾아 삭제하고 결과를 반환
search_at(i) : i 번째 데이터를 반환. 유효하지 않은 인덱스라면 에러 발생
search(e) : 데이터 e가 처음으로 나타나는 인덱스를 찾아 반환
2. 구현
# 양방향 연결리스트 클래스
class DoublyLinkedList:
# 노드 클래스
class __Node:
# 노드 생성자
def __init__(self, e):
# 데이터
self.data = e
# 다음 노드
self.next = None
# 이전 노드
self.prev = None
# 리스트 생성자
def __init__(self):
# head
self.__head = None
# tail
self.__tail = None
# 현재 노드 (iterator 구현을 위한 필드)
self.__it = self.__Node(0)
# 리스트 크기
self.__size = 0
# 삽입 메소드
def insert(self, e, i=-1):
# 삽입할 노드 생성
new_node = self.__Node(e)
# 인덱스가 생략됐거나 마지막 인덱스인 경우 맨 끝에 삽입
if i < 0 or i == self.__size:
# 리스트가 비어있다면 head = tail = new_node
if not self.__head:
self.__head = self.__tail = new_node
# 리스트가 비어있지 않다면 마지막 노드 뒤에 삽입
else:
self.__tail.next = new_node
new_node.prev = self.__tail
self.__tail = new_node
# 마지막 노드가 아닌 인덱스가 주어졌을 경우
else:
# 유효하지 않은 인덱스라면 IndexError 발생
if i > self.__size:
raise IndexError
# 인덱스가 0이라면 첫 노드의 앞 부분에 삽입
if i == 0:
self.__head.prev = new_node
new_node.next = self.__head
self.__head = new_node
# 그렇지 않다면 해당 인덱스의 노드 앞 부분에 삽입
else:
cur = self.__head
for _ in range(i):
cur = cur.next
cur.prev.next = new_node
new_node.prev = cur.prev
cur.prev = new_node
new_node.next = cur
# 리스트의 크기 1 증가
self.__size += 1
# 탐색 메소드 - 인덱스
def search_at(self, i):
# 유효하지 않은 인덱스라면 IndexError 발생
if i < 0 or i >= self.__size:
raise IndexError
# head 부터 i만큼 다음 노드로 이동
cur = self.__head
for _ in range(i):
cur = cur.next
# 노드의 데이터 반환
return cur.data
# 탐색 메소드 - 데이터
def search(self, e):
cur = self.__head
idx = 0
# 데이터 값이 e인 노드가 나올 때 까지 탐색
while cur and cur.data != e:
cur = cur.next
idx += 1
# 데이터 값이 e인 노드가 없을 경우 ValueError 발생
if not cur:
raise ValueError
# 데이터 값이 e인 노드가 처음으로 나타난 인덱스 반환
return idx
# i 번째 노드 삭제 메소드
def delete_at(self, i):
# 유효하지 않은 인덱스라면 IndexError 발생
if i < 0 or i >= self.__size:
raise IndexError
# head 부터 i 만큼 다음 노드로 이동
cur = self.__head
for _ in range(i):
cur = cur.next
# 반환할 노드의 데이터를 저장
res = cur.data
# 앞, 뒤 노드가 서로 연결되도록 조정
# head, tail 을 삭제한 경우 head, tail 재지정
if cur.prev:
cur.prev.next = cur.next
else:
self.__head = cur.next
if cur.next:
cur.next.prev = cur.prev
else:
self.__tail = cur.prev
# 리스트 크기 1 감소
self.__size -= 1
# 삭제한 데이터 반환
return res
# 처음으로 나타나는 데이터 e 삭제 메소드
def delete(self, e):
# 데이터 삭제 시도
try:
# search 메소드를 호출하여 데이터의 인덱스를 구함
idx = self.search(e)
# delete_at 메소드를 호출하여 데이터 삭제
self.delete_at(idx)
# 삭제성공. True 반환
return True
# 존재하지 않는 데이터라면 삭제에 실패. False 반환
except ValueError:
return False
# len 함수의 결과로 sef.__size 반환
def __len__(self):
return self.__size
# 이터레이터 구현
def __iter__(self):
# 이터레이션을 위한 self.__it 객체의 next 를 self.__head 로 하고 self 를 반환
self.__it.next = self.__head
return self
def __next__(self):
# 다음 노드가 있다면 self.__it = self.__it.next 후 self.__it 의 데이터값 반환
if self.__it.next:
self.__it = self.__it.next
return self.__it.data
# 없다면 이터레이션 종료
else:
raise StopIteration
# 테스트
def main():
# 연결 리스트 생성
dlist = DoublyLinkedList()
# 데이터 삽입
dlist.insert(3)
dlist.insert(1)
dlist.insert(2)
dlist.insert(4)
dlist.insert(0)
dlist.insert(6)
dlist.insert(7)
dlist.insert(9)
# 데이터 4 삭제
dlist.delete(4)
# 첫 번째 데이터(3) 삭제
dlist.delete_at(0)
# 3 번째 데이터(6) 삭제
dlist.delete_at(3)
# Python 의 list 로 변환하여 출력
print(list(dlist))
ADT에서 언급한대로 리스트의 기능을 구현
__len__(self) 를 구현하여 len 함수를 호출하면 리스트의 크기를 반환하도록 함
__iter__(self) 와 __next__(self) 를 구현하여 이터레이터로서 동작하도록 구현. for 문이나 list() 에 사용 가능.
단방향 연결 리스트나 원형 연결 리스트의 경우 양방향 연결 리스트의 코드를 조금 수정하는 것 만으로 구현할 수